도입부
상품 링크만으로 위시리스트를 등록하는 기능을 만들고 싶었지만, 이를 구현하는 과정에서는 크롤링과 상태 전달 문제를 함께 해결해야 했다. 이 글에서는 상품 링크 기반 자동 등록 기능을 구현하면서 마주한 제약과, 이를 해결하기 위해 구성한 비동기 크롤링 아키텍처를 설명한다. 프로젝트 전반에 대한 소개는 별도의 글에서 다루고, 여기서는 해당 기능의 구현 과정에만 집중한다.
위시리스트 기능에서 가장 먼저 해결하고 싶었던 문제는 사용자가 상품 정보를 직접 입력해야 한다는 점이었다. 상품명, 가격, 이미지 URL까지 직접 입력하게 하면 등록 과정이 길어지고, 그만큼 이탈 가능성도 커진다.
그래서 상품 링크만 입력받고, 서버가 해당 페이지에서 필요한 상품 정보를 추출해 등록에 필요한 값을 자동으로 채우는 방식을 구상했다. 목표는 사용자가 URL만 붙여넣으면, 서비스가 필요한 정보를 대신 수집해 등록 과정을 최대한 단순화하는 것이었다.
하지만 대부분의 쇼핑몰은 이런 목적의 공개 API를 제공하지 않았고, 결국 상품 정보를 수집하려면 페이지를 직접 읽어오는 방식이 필요했다. 문제는 많은 쇼핑몰이 자동화된 접근을 허용하지 않는다는 점이었다.
여러 쇼핑몰의 robots.txt를 확인해보니, 일부 검색 엔진 봇을 제외하면 일반적인 크롤링 접근은 대부분 허용되어 있지 않았다.
기술적으로는 User-Agent를 허용된 검색 봇 처럼 위장하는 우회도 생각할 수 있었다. 하지만 이는 플랫폼이 의도한 사용방식이 아니고, 데모 단계의 소량 트래픽이라도 정식 서비스까지 같은 방식으로 이어가면 법적 리스크가 커질 수 있다고 봤다. 그래서 이 방법은 채택하지 않았다.
여기서 자연스럽게 한 가지 의문이 생겼다. 카카오톡 같은 메신저에서 URL을 보낼때 자동으로 생성되는 URL Preview는 어떤 방식으로 만들어질까?
URL Preview
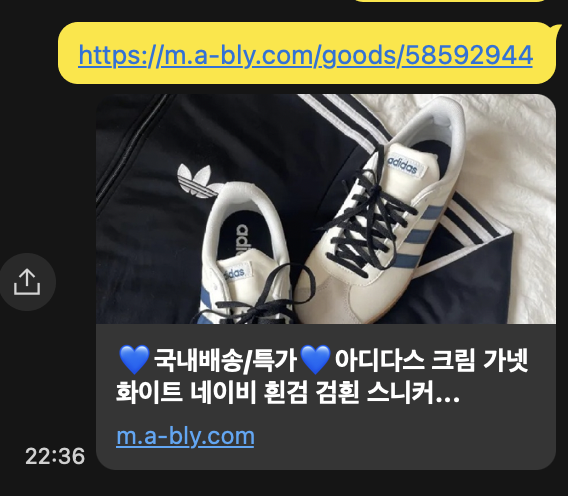
많은 서비스의 URL Preview는 페이지의 Open Graph 같은 메타 태그를 기반으로 생성된다.
예를 들어 해당 상품 페이지의 HTML을 보면 다음과 같은 메타 태그가 포함되어 있다.
...
<meta name="title" content="💙국내배송/특가💙아디다스 크림 가넷 화이트 네이비 흰검 검흰 스니커즈 운동화 가젤 네오 코트 남녀공용 커플 신발 - 에이블리"/>
<meta name="description" content="아디다스 💙국내배송/특가💙아디다스 크림 가넷 화이트 네이비 흰검 검흰 스니커즈 운동화 가젤 네오 코트 남녀공용 커플 신발 신발, 스니커즈"/>
<meta property="og:type" content="website"/>
<meta property="og:url" content="https://m.a-bly.com/goods/58592944?tracking_content=9b2258783a&airbridge_referrer=airbridge%3Dtrue%26client_id%3D88817bd7-d557-4d58-8d0a-d8b44a5ff23b%26event_uuid%3Df18a7b1a-b3ed-42ae-bd99-58947cc7ed4d%26referrer_timestamp%3D1771467407711%26short_id%3De8951i%26channel%3Dapp__goods_detail%26campaign%3D%255BABLY%255D%2520%25EC%2583%2581%25ED%2592%2588%2520%25EB%25A7%2581%25ED%2581%25AC%2520%25EA%25B3%25B5%25EC%259C%25A0%26tracking_template_id%3D2b7826367a653fc2fab265c8584d0a8d%26ad_creative%3Dm2755240%26content%3D16%26term%3D58592944%26sub_id%3Dgoods%26og_tag_id%3D395548175%26routing_short_id%3De8951i&utm_source=app__goods_detail&utm_campaign=%5BABLY%5D%20%EC%83%81%ED%92%88%20%EB%A7%81%ED%81%AC%20%EA%B3%B5%EC%9C%A0&utm_medium=goods&utm_term=58592944&utm_content=16"/>
<meta property="og:title" content="💙국내배송/특가💙아디다스 크림 가넷 화이트 네이비 흰검 검흰 스니커즈 운동화 가젤 네오 코트 남녀공용 커플 신발 - 에이블리"/>
<meta property="og:description" content="아디다스 💙국내배송/특가💙아디다스 크림 가넷 화이트 네이비 흰검 검흰 스니커즈 운동화 가젤 네오 코트 남녀공용 커플 신발 신발, 스니커즈"/>
<meta property="og:image" content="https://d3ha2047wt6x28.cloudfront.net/facweZjviq4/pr:GOODS_DETAIL/czM6Ly9hYmx5LWltYWdlLWxlZ2FjeS9kYXRhL2dvb2RzLzIwMjUxMjI5XzE3NjY5NzQ2NTY0NTM4ODVtLmpwZw"/>
...
일반적인 URL Preview 생성과정은 대략 다음과 같이 정리할 수 있다.
- 사용자가 URL이 포함된 메시지를 전송한다.
- 서버는 해당 URL의 HTML을 가져온 뒤
og:title,og:image같은 메타 태그를 파싱해 제목과 대표 이미지 등의 정보를 추출한다. - 추출한 데이터를 클라이언트에 전달하고, 클라이언트는 이를 미리 정해진 UI로 렌더링 한다.
URL Preview를 서버에서 생성하는 이유는 크게 CORS, 보안, 일관성의 세가지로 정리할 수 있다.
- CORS 문제
- 브라우저 환경의 클라이언트가 외부 URL의 HTML을 직접 가져오려 하면 대부분 CORS 정책에 막힌다. 반면 서버는 브라우저의 동일 출처 제약을 받지 않기 때문에 외부 페이지를 직접 수집할 수 있다.
- 보안 문제
- 클라이언트가 임의의 외부 URL에 직접 접근하도록 만들면 악성 링크에 노출될 가능성이 커진다. 서버 측 수집도 안전하지 않은 것은 아니지만, 최소한 요청 정책과 화이트리스트, 리다이렉트 제한 같은 통제를 서버에서 일관되게 적용할 수 있다.
- 일관성 문제
- 같은 URL이라도 사용자 환경, 로그인 상태, 지역, 기기에 따라 응답 내용이 달라질 수 있다. 서버에서 일정한 조건으로 수집하고 가공하면 더 예측 가능한 결과를 제공하기 쉽다.
다만 이 방식 역시 결국 서버가 페이지를 요청해 메타데이터를 읽어와야 한다는 점에서 일종의 크롤링에 가깝다. 실제로 여러 쇼핑몰의 robots.txt를 확인해보면 일반적인 봇은 제한하면서도, 카카오톡 같은 주요 메신저의 프리뷰 봇은 허용하는 경우가 있었다. URL Preview가 동작하는 배경도 여기에 있다고 볼 수 있다
메타 태그만으로는 가격이나 브랜드처럼 필요한 정보가 모두 제공되지 않는 경우도 있었다. 그래서 보조적으로 활용할 수 있는 다른 데이터 소스를 찾다가 JSON-LD를 함께 확인하게 됐다.
JSON-LD
JSON-LD란 HTML 문서 안에 script 태그로 삽입할 수 있는 구조화 데이터 형식이다. 검색 엔진이나 외부 서비스가 페이지의 핵심 정보를 기계적으로 이해할 수 있도록 돕는 용도로 자주 사용된다.
쇼핑몰 페이지에서는 상품명, 가격, 브랜드, 재고 상태 같은 정보를 JSON-LD로 제공하는 경우가 많다.
...
<script type="application/ld+json">{
"@context": "https://schema.org/",
"@type": "Product",
"name": "💙국내배송/특가💙아디다스 크림 가넷 화이트 네이비 흰검 검흰 스니커즈 운동화 가젤 네오 코트 남녀공용 커플 신발",
"description": "아디다스 💙국내배송/특가💙아디다스 크림 가넷 화이트 네이비 흰검 검흰 스니커즈 운동화 가젤 네오 코트 남녀공용 커플 신발 신발, 스니커즈",
"image": [
"https://d3ha2047wt6x28.cloudfront.net/facweZjviq4/pr:GOODS_DETAIL/czM6Ly9hYmx5LWltYWdlLWxlZ2FjeS9kYXRhL2dvb2RzLzIwMjUxMjI5XzE3NjY5NzQ2NTY0NTM4ODVtLmpwZw",
"https://d3ha2047wt6x28.cloudfront.net/jn2J7cAML-Y/pr:GOODS_DETAIL/czM6Ly9hYmx5LWltYWdlLWxlZ2FjeS9kYXRhL2dvb2RzLzIwMjUxMjI5XzE3NjY5NzQ2Njc2NjkxNzFtLmpwZw",
"https://d3ha2047wt6x28.cloudfront.net/ylq_DrhRgfs/pr:GOODS_DETAIL/czM6Ly9hYmx5LWltYWdlLWxlZ2FjeS9kYXRhL2dvb2RzLzIwMjUxMjI5XzE3NjY5NzQ2NzAxMzk4NjRtLmpwZw",
"https://d3ha2047wt6x28.cloudfront.net/tg5swtiztP0/pr:GOODS_DETAIL/czM6Ly9hYmx5LWltYWdlLWxlZ2FjeS9kYXRhL2dvb2RzLzIwMjUxMjI5XzE3NjY5NzQ2NzQ4ODIxMTJtLmpwZw"
],
"brand": {
"@type": "Brand",
"name": "아디다스"
},
"manufacturer": {
"@type": "Organization",
"name": "아디다스"
},
"category": "신발, 스니커즈",
"sku": "47243-58592944",
"productID": "58592944",
"offers": {
"@type": "Offer",
"url": "https://m.a-bly.com/goods/58592944",
"priceCurrency": "KRW",
"price": 65900,
"availability": "https://schema.org/InStock"
}
}</script>
...
실제로는 대체로 이런 형태로 포함되어 있다.
이 JSON-LD가 초기 HTML에 포함되어 있다면, 별도의 동적 렌더링 없이도 필요한 상품 정보를 추출할 수 있다.
그래서 메타 태그와 함께 JSON-LD도 수집 대상으로 활용하기로 했다.
다만 메타 태그든 JSON-LD든, 결국 출발점은 서버가 대상 페이지의 HTML을 받아오는 것이다.
즉, 기술적으로는 동적 브라우저 크롤링을 피할 수 있었지만, 외부 페이지를 수집한다는 점 자체는 그대로 남아 있었다.
robots.txt를 확인해보면 대부분의 쇼핑몰은 일반적인 크롤링 봇을 허용하지 않았다.
허용된 봇의 User-Agent를 위장하는 방식도 생각할 수 있었지만, 이는 플랫폼이 의도한 사용 방식이 아니므로 실제 서비스 구조로 채택하지 않았다.
데모 목적의 비상업적 활용이었지만, 다음 원칙을 두고 크롤링 범위를 제한했다.
- 하나의 플랫폼에 과도한 동시 요청이 몰리지 않도록 제한하기
- 최근에 수집한 상품에는 쿨다운을 적용하고, 쿨다운 기간 중 들어온 요청에는 기존 캐시 데이터를 우선 반환하기
- 허용된 플랫폼만 URL 화이트리스트로 관리하고, 그 외 도메인에 대한 요청은 차단하기
이를 통해 기능 시연에 필요한 범위 안에서만 수집을 수행하고, 대상 플랫폼의 부하와 오남용 가능성을 줄이려고 했다.
아키텍처 구조
전체 흐름
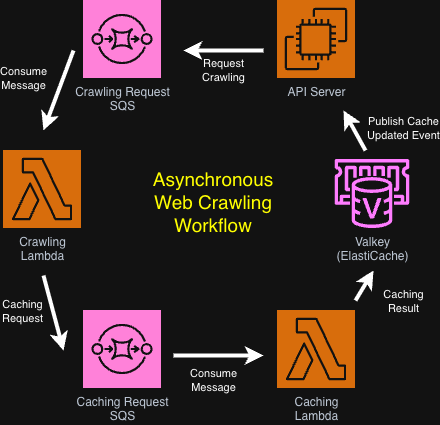
위 다이어그램은 상품 크롤링과 캐싱 과정을 단순화한 전체 워크플로우다.
이미 최근에 크롤링된 상품은 캐시에서 바로 반환되지만, 해당 흐름은 다이어그램에서 생략했다.
이후 흐름은 캐시 적중과 캐시 미스(만료) 두 가지 경우로 나누어 설명한다.
캐시 미스(캐시 만료)
캐시 미스는 해당 상품이 처음 요청된 경우이거나, 기존 데이터가 만료된 경우를 의미한다.
이 경우 새로운 크롤링 작업을 수행하고, 결과를 DB와 Valkey에 저장한다.
크롤링 요청
먼저 Valkey 에 해당 jobId의 상태를 PENDING으로 기록한다. 이를 통해 이후 비동기 작업의 진행 상태를 추적할 수 있도록 한다.
// Valkey 캐시 (키 : 값)
status:crawl:e7d5ce5c-5d3a-43bb-8c93-26216273f883:status="PENDING"
이후 API 서버는 SQS에 크롤링 작업 메시지를 발행한다.
// 메시지 내용
{
"jobId": "e7d5ce5c-5d3a-43bb-8c93-26216273f883",
"url": "https://www.musinsa.com/products/5416073"
}
API는 즉시 응답을 반환하고, 클라이언트에는 jobId를 전달한다.
이후 작업 결과는 이 jobId를 기준으로 조회할 수 있다.
// API 응답
{
"jobId": "e7d5ce5c-5d3a-43bb-8c93-26216273f883",
"requestedAt": "2025. 03. 11. 오전 9:00:00"
}
이후 클라이언트는 SSE 연결을 통해 해당 jobId의 완료 이벤트를 실시간으로 수신한다.
크롤링 람다 작업 수행
SQS에 메시지가 도착하면 크롤링 Lambda가 트리거되어 해당 작업을 처리한다.
Lambda는 대상 URL의 HTML을 가져온 뒤, 메타 태그와 JSON-LD 데이터를 추출한다.
이후 결과를 바로 저장하지 않고 캐싱 전용 SQS로 메시지를 전달해 다음 단계로 넘긴다.
이를 통해 크롤링과 데이터 가공/저장 단계를 분리해 각 작업의 책임을 명확히 했다.
// 메시지 내용
{
"type": "CRAWL_CACHING",
"platformDomain": "www.musinsa.com",
"productId" : "5416073",
"jobId" : "e7d5ce5c-5d3a-43bb-8c93-26216273f883",
"result" : {
"meta": {...},
"seoJson": {...}
}
}
동시에 Valkey에 cooldown 키를 설정해 일정 시간 동안 동일 상품에 대한 중복 크롤링을 방지한다. 이는 대상 플랫폼의 부하를 줄이기 위한 장치다.
// Valkey 캐시 (키 : 값)
cooldown:crawl:platforms:www.musinsa.com:products:5416073 = "1"
캐싱 람다 작업 수행
크롤링 Lambda가 올린 메시지를 다시 캐싱 Lambda가 소비하여 이어서 작업을 진행하게 된다.
캐싱 Lambda 는 전달받은 meta, seoJson(JSON-LD 기반 데이터)를 기반으로, 사전에 정의한 경로 프리셋을 이용해 가격, 상품명, 브랜드, 이미지 URL 등을 추출한다.
// 값 위치 계층 구조 프리셋
...
const pricePath = { // 가격 정보 위치 경로
"www.musinsa.com": [
[
"seoJson",
"props",
"pageProps",
"meta",
"data",
"goodsPrice",
"salePrice",
],
[
"seoJson",
"props",
"pageProps",
"meta",
"data",
"goodsPrice",
"normalPrice",
],
],
"www.29cm.co.kr":[
["seoJson","offers","price"]
]
};
const brandPath = { // 브랜드명 정보 위치 정보
"www.musinsa.com" : [
"seoJson",
"props",
"pageProps",
"meta",
"data",
"brandInfo",
"brandName",
],
"www.29cm.co.kr": ["seoJson","brand","name"]
}
const namePath = { // 상품 명 정보 위치 정보
"www.musinsa.com": [["meta", "twitter:title"]],
"www.29cm.co.kr": [["meta","description"]]
};
...
// 프리셋 기반 값 추출 함수
const getValue = (obj, path) => {
for (const key of path) {
obj = obj[key];
}
return obj;
};
추출한 값은 추가 가공을 거쳐 RDBMS에 저장된다.
캐시 만료로 인해 크롤링을 진행해서 기존 상품정보가 저장되어 있다면 덮어쓰기를 진행한다.
이미지 URL은 별도로 요청해 S3에 업로드 하고, DB에는 해당 파일 경로만 저장한다.
모든 작업이 완료되면 Valkey에 해당 jobId의 상태를 DONE으로 변경하고, 결과 데이터의 ID를 함께 기록한다.
status:crawl:e7d5ce5c-5d3a-43bb-8c93-26216273f883:status = "DONE"
status:crawl:e7d5ce5c-5d3a-43bb-8c93-26216273f883:resultId = "1"
status:crawl:e7d5ce5c-5d3a-43bb-8c93-26216273f883:source = "CRAWLED"
캐시 적중
최근에 동일 상품에 대한 크롤링 이력이 존재하면 캐시 적중으로 판단한다.
Lambda는 플랫폼 도메인과 상품 ID를 기반으로 Valkey의 cooldown 키를 조회해 최근 수집 여부를 확인한다.
존재할 경우 추가 크롤링 없이 기존 DB 레코드를 사용하고, Valkey에는 해당 결과를 즉시 반환할 수 있도록 상태를 기록한다.
status:crawl:e7d5ce5c-5d3a-43bb-8c93-26216273f883:status = "DONE"
status:crawl:e7d5ce5c-5d3a-43bb-8c93-26216273f883:resultId = "1"
status:crawl:e7d5ce5c-5d3a-43bb-8c93-26216273f883:source = "COOLDOWN"
결과 값을 API 서버에서 감지
여기까지의 흐름만 보면 결과는 Valkey에 기록되지만, API 서버가 그 변경을 즉시 인지할 방법은 없었다.
또한 로드 밸런서 뒤에 API 서버가 두 대로 분산되어 있었기 때문에, 완료 사실을 Lambda나 다른 서버가 직접 알리는 방식은 로직이 더 복잡해질 수 있었다.
이를 해결하기 위해 API 서버가 Valkey의 keyspace 이벤트를 구독하도록 구성했다.
Valkey 캐시 Keyspace 이벤트가 발생하면 두 API 서버는 해당 변경 사실을 전달받는다.
이벤트를 수신한 API 서버는 해당 jobId와 연결된 SSE 세션을 확인하고, 일치하는 경우 EventEmitter를 통해 대기 중인 SSE 스트림으로 전달한다.
클라이언트는 이를 수신한 뒤 결과 ID를 받고 SSE 연결을 종료한다.
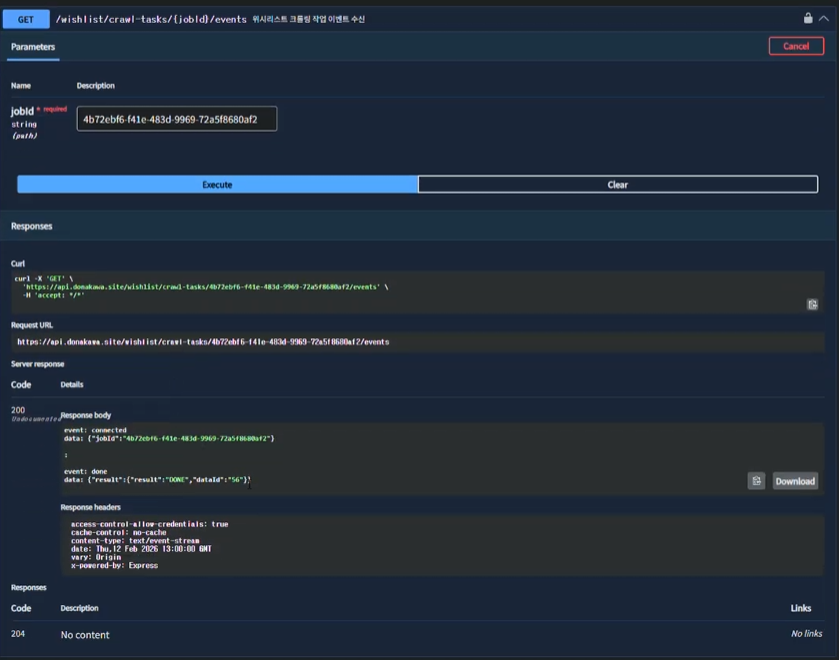
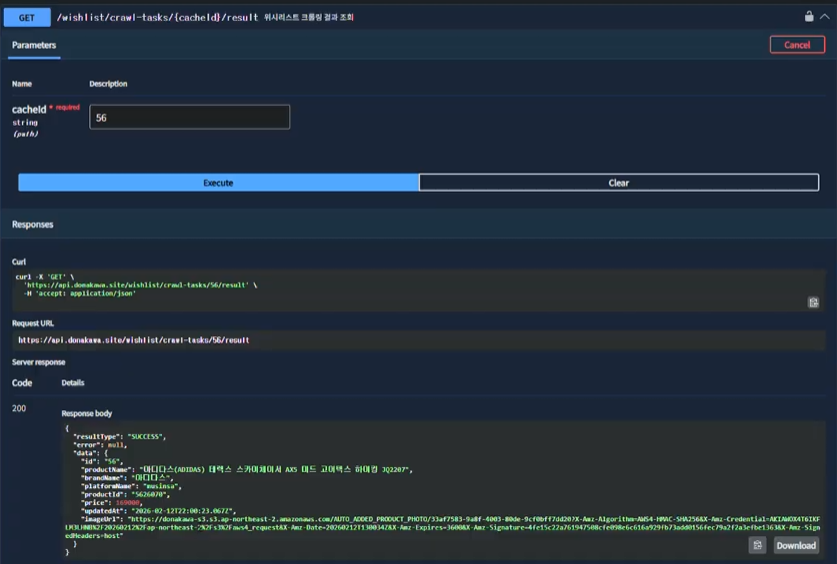
최종 결과 조회
이후 클라이언트는 SSE로 전달받은 resultId를 이용해 조회 API를 호출하고, 최종적으로 크롤링 결과 데이터를 가져온다.
마무리
정리하면 이 구조는 상품 링크 등록 경험을 단순화 하기 위해, 크롤링/가공/상태 전달을 비동기 워크 플로우로 분리한 설계였다.
SQS와 Lambda로 작업을 나누고, Valkey와 SSE를 이용해 상태를 전달함으로써 사용자는 긴 대기 없이 결과를 받을 수 있도록 했다.
다만 이를 실 서비스에 적용하기에는 명확한 한계점이 존재한다.
메타 태그와 JSON-LD를 활용해 동적 크롤링을 줄일 수 있었지만, 외부 쇼핑몰 페이지를 수집한다는 한계 자체는 남아있다. 실제 서비스로 확장하려면 크롤링 중심 접근 보다 제휴 기반 데이터 연동이나 공식 API 확보가 더 적절한 방향이라고 본다.

